gekennzeichnet.
gekennzeichnet.
📖 Über dieses Dokument
Dieses Dokument vermittelt Wissen in strukturierter Form. Fachbegriffe werden direkt im Text erklärt – fahren Sie mit der Maus über unterstrichene Begriffe um eine Kurzerklärung zu sehen.
Komplexe Konzepte lassen sich schrittweise vereinfachen: Klicken Sie auf „Einfacher erklären" um eine zugänglichere Darstellung desselben Inhalts zu öffnen – von formaler Fachsprache bis zur anschaulichen Alltagsanalogie.
Definitionen, Theoreme, Algorithmen und Beispiele sind semantisch ausgezeichnet und aufeinander abgestimmt. Das Glossar in der Seitenleiste fasst alle Fachbegriffe des Dokuments alphabetisch zusammen.
Im Präsentationsmodus (⊞) wird jeder Inhaltsblock einzeln angezeigt – geeignet für Vorträge oder konzentriertes Lesen. Navigation per Pfeiltasten oder Klick in den Fortschrittsbalken.
📋 Inhaltsverzeichnis
- Was ist ein KI-Unternehmens-Wiki?
- Wie funktioniert das technisch? Drei Kernkonzepte
- Large Language Model (LLM): Das sprachliche Herzstück
- Embeddings und Embedding-Modelle: Wie Bedeutung zur Zahl wird
- Vektordatenbank: Das semantische Gedächtnis
- RAG: Retrieval-Augmented Generation
- Welche Dokumente und Datenquellen können eingebunden werden?
- Warum Cloud-KI bei tausenden Dokumenten scheitert
- Das Token-Problem: Was sind Token und warum kosten sie Geld?
- Lokale KI: Datensicherheit als struktureller Vorteil
- DSGVO-Konformität ohne Kompromisse
- EU AI Act: Lokale KI macht Compliance leichter
- Praxisbeispiele: Wer profitiert besonders?
- Implementierung: Was ist zu beachten?
- Fazit
KI-gestütztes Unternehmens-Wiki: Firmenwissen intelligent befragen statt endlos suchen
Ein KI-gestütztes Unternehmens-Wiki erschliesst Firmendokumente semantisch und beantwortet natürlichsprachliche Fragen präzise mit Quellenverweis. Der Artikel erklärt die RAG-Architektur, beleuchtet die Schwächen von Cloud-KI und zeigt, warum lokale KI datenschutzrechtlich und wirtschaftlich überlegen ist.
Was ist ein KI-Unternehmens-Wiki?
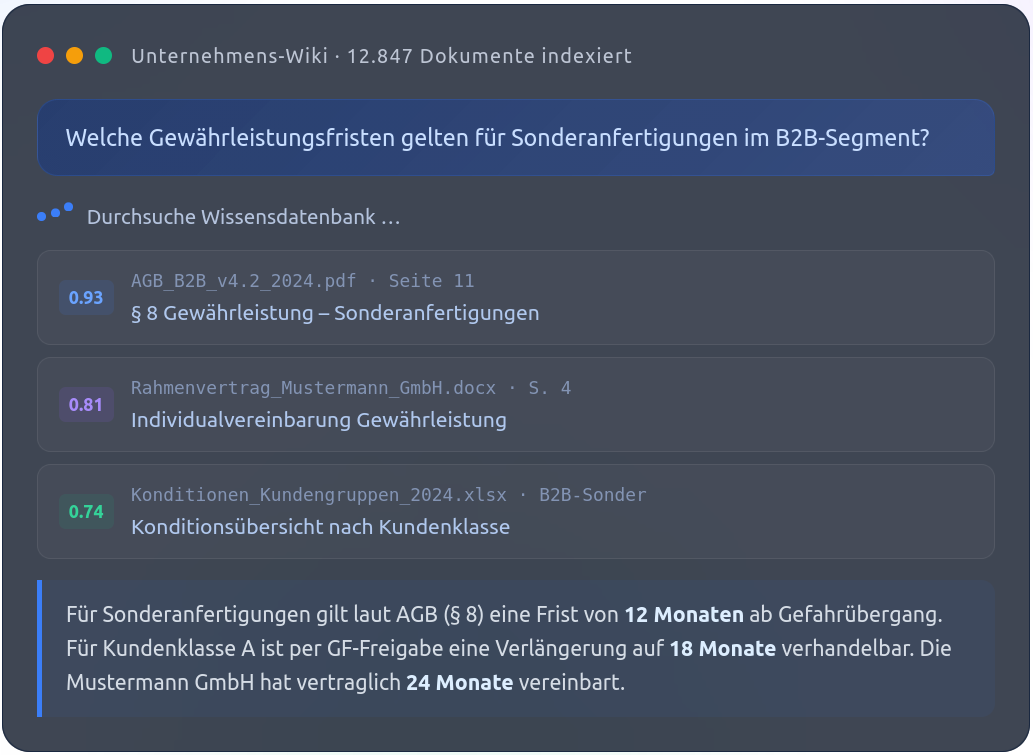
Ein KI-gestütztes Unternehmens-Wiki ist keine klassische Suchmaschine und auch kein starres Dokumentenarchiv. Es ist ein intelligentes System, das firmeneigene Dokumente, Datenbanken und Drittsysteme semantisch erschliesst und auf natürlichsprachliche Fragen präzise antwortet. Das System erkennt, dass Wie eskaliere ich einen Supportfall? und Was mache ich, wenn ein Ticket nicht weitergeht? dieselbe Antwort erfordern, auch wenn kein einziges Wort übereinstimmt.
Der entscheidende Unterschied zu herkömmlichen Suchwerkzeugen: Klassische Volltextsuche findet Dokumente, in denen das gesuchte Wort vorkommt. Das KI-Wiki findet Dokumente, die die gesuchte Bedeutung enthalten – auch wenn der Nutzer andere Wörter verwendet als der Autor des Dokuments. Das ist kein sprachlicher Trick, sondern ein fundamentaler technischer Unterschied, der den Alltag der Wissensarbeit grundlegend verändert.
KI Unternehmens-Wiki –
so funktioniert es
Firmendokumente und Systeme semantisch erschlossen – präzise Antworten mit Quellenverweis, vollständig lokal betrieben.
PDF-Dokumente
Verträge, Berichte, Handbücher
Word / Excel
Protokolle, Tabellen, Notizen
PowerPoint
Präsentationen, Schulungen
Datenbanken
SQL, intern, strukturiert
ERP / CRM
SAP, Salesforce, custom, iTWO
Vektordatenbank
Semantische Ähnlichkeitssuche
Sprachmodell (LLM)
Antwort auf Basis der Treffer
Antwort + Quellenverweis
Präzise · Nachvollziehbar · Belegt
Natürliche Sprache
Fragen in Alltagssprache
Quellennachweis
Datei, Seite, Abschnitt
100 % lokal
Daten verlassen nie das Haus
Fachvokabular
Internes Wissen verstehen
AI Act konform
Vollständige Transparenz
- Direkte Antworten statt Trefferlisten: Das System zitiert die relevante Passage aus dem Quelldokument und formuliert eine verständliche Antwort – keine Liste von Dokumenten, die der Nutzer selbst durchsuchen muss.
- Quellentransparenz: Jede Antwort enthält den Verweis auf das Originaldokument (Dateiname, Seitenangabe). Vertrauen in die Antwort entsteht durch Nachvollziehbarkeit.
- Firmenspezifisches Vokabular: Interne Begriffe, Produktnamen und Abkürzungen werden verstanden – das System muss nicht auf allgemeines Sprachverständnis beschränkt bleiben.
- Multiformat-Unterstützung: PDF, Word, Excel, PowerPoint, Textdateien sowie Datenbankanbindungen werden unterstützt. Das Wissen steckt oft in unterschiedlichsten Formaten – das System erschliesst sie alle.
- Systemintegration: Anbindung an ERP, CRM, Ticketsysteme oder andere Drittsysteme möglich. Das KI-Wiki wird zur zentralen Auskunftsschicht über alle vorhandenen Systeme.
- Rollenbasierter Zugriff: Der Vertrieb sieht andere Dokumente als die Buchhaltung. Zugriffsrechte aus bestehenden Systemen lassen sich auf die KI-Ebene übertragen.
Wie funktioniert das technisch? Drei Kernkonzepte
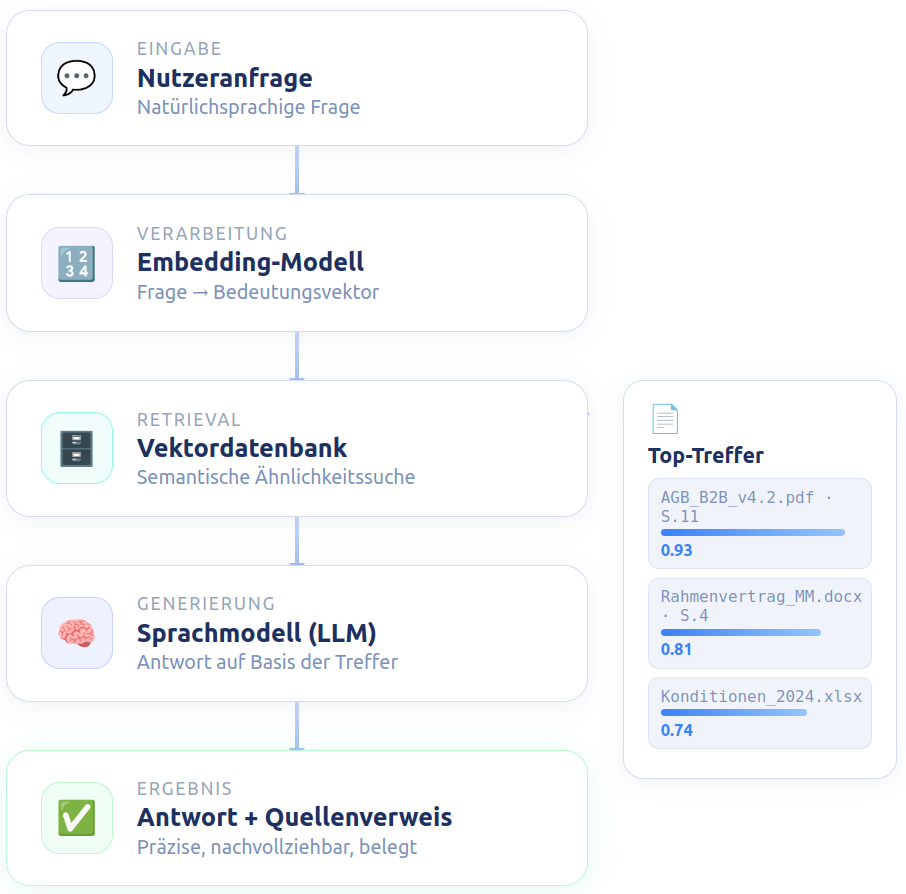
Das System basiert auf drei zusammenwirkenden Technologien: einem Large Language Model (LLM), einem Embedding-Modell und einer Vektordatenbank. Das Zusammenspiel dieser Komponenten wird als RAG bezeichnet.
Large Language Model (LLM): Das sprachliche Herzstück
Embeddings und Embedding-Modelle: Wie Bedeutung zur Zahl wird
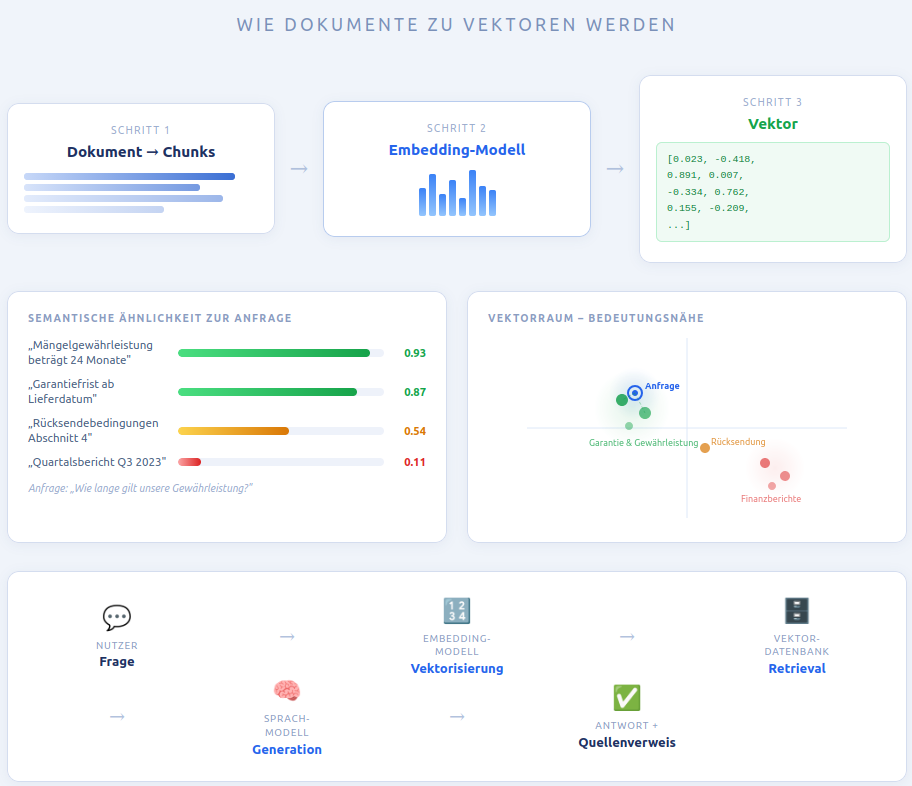
Vektordatenbank: Das semantische Gedächtnis
- Vektor (Embedding): Die numerische Bedeutungsrepräsentation des Textabschnitts.
- Originaltext (Chunk): Der Quelltext des Abschnitts, der dem LLM als Kontext übergeben wird.
- Metadaten: Dateiname, Dokumenttyp, Datum, Seitennummer, Zugriffsrechte – Grundlage für Quellentransparenz und rollenbasierten Zugriff.
RAG: Retrieval-Augmented Generation
Welche Dokumente und Datenquellen können eingebunden werden?
Ein modernes KI-Wiki ist nicht auf Dateien beschränkt. Es kann eine breite Palette an Quellen erschliessen – und besonders wertvoll wird es, wenn Informationen aus mehreren Systemen zusammenspielen.
| Kategorie | Beispiele |
|---|---|
| Dokumentenformate | PDF (mit OCR), Word (.docx), Excel (.xlsx), PowerPoint (.pptx), Textdateien, Markdown, HTML, archivierte E-Mails |
| Relationale Datenbanken | PostgreSQL, MySQL, MSSQL |
| ERP-Systeme | SAP, Sage, Navision / Business Central |
| CRM-Systeme | Salesforce, HubSpot, Zoho, Microsoft Dynamics |
| Ticketsysteme | Jira, Freshdesk, Zendesk |
| Wikis und Intranets | Confluence, SharePoint |
| Schnittstellen | REST-APIs beliebiger Drittsysteme |
Warum Cloud-KI bei tausenden Dokumenten scheitert
Wer ein Unternehmens-Wiki auf Basis von Cloud-KI-Diensten aufbauen möchte, stösst schnell an strukturelle Grenzen – nicht nur technische, sondern auch wirtschaftliche und rechtliche.
Das Token-Problem: Was sind Token und warum kosten sie Geld?
Weitere Skalierungsprobleme
- Kontextfenster-Grenzen: Auch bei grossen Kontextfenstern (128k Token) lässt die Qualität bei sehr langen Kontexten nach – bekannt als Lost-in-the-Middle-Phänomen.
- Rate Limits: API-Anfragen werden gedrosselt; bei parallelen Nutzern entstehen Wartezeiten.
- Datensouveränität: Dokumente verlassen das Unternehmen – mit allen datenschutzrechtlichen Konsequenzen.
- Vendor Lock-in: Ändert der Anbieter Preise, Modelle oder AGB, ist das gesamte System betroffen.
Lokale KI: Datensicherheit als struktureller Vorteil
Lokal meint in diesem Kontext nicht zwingend den eigenen Serverraum. Es meint: Die KI-Infrastruktur läuft in einer Umgebung, die vollständig unter der Kontrolle des Unternehmens steht – ob on-premises, auf einer dedizierten VM beim Hosting-Anbieter oder in einer Private Cloud mit klarer Datentrennung. Kein Token der Firmendokumente wird an externe APIs gesendet.
DSGVO-Konformität ohne Kompromisse
Wer Firmendokumente an Cloud-KI-Dienste sendet, muss sich intensiv mit Auftragsverarbeitung (Art. 28 DSGVO) befassen sowie den Drittlandtransfer nach Art. 44 ff. DSGVO prüfen. Bei lokaler KI entfallen diese Fragen strukturell: Es gibt keinen Auftragsverarbeiter, keinen Drittlandtransfer und keine Nutzung für Modelltraining.
- Kanzleien und steuerberatende Berufe (Mandantendaten, Berufsgeheimnis)
- Medizinische Einrichtungen (Gesundheitsdaten nach Art. 9 DSGVO)
- Unternehmen mit Betriebs- und Geschäftsgeheimnissen (§ 2 GeschGehG)
- Öffentliche Stellen und Behörden
- Unternehmen mit ISO 27001 oder ähnlichen Zertifizierungen
EU AI Act: Lokale KI macht Compliance leichter
Der EU AI Act (Verordnung (EU) 2024/1689) tritt seit August 2024 schrittweise in Kraft und reguliert KI-Systeme nach Risikoklassen. Für ein Unternehmens-Wiki sind vor allem Transparenzpflichten und – bei hochrisikorelevanten Bereichen wie HR-Entscheidungsunterstützung oder kritischer Infrastruktur – Konformitätsdokumentation relevant.
- Erklärbarkeit strukturell erfüllt: Antworten basieren auf nachweisbaren Quelltexten. Die verwendeten Dokumentenabschnitte sind protokollierbar, das eingesetzte Modell ist bekannt und unveränderlich.
- Konformitätsdokumentation vollständig möglich: Modellname und -version, Trainingsgrundlage, verarbeitete Datenkategorien sowie Zugriffsberechtigungen und Protokollierung sind bei lokaler KI vollständig dokumentierbar – bei Cloud-Diensten oft nicht.
- Keine stillen Modell-Wechsel: Bei Cloud-Diensten kann der Anbieter das zugrunde liegende Modell jederzeit wechseln. Bei lokaler KI bleibt das Modell stabil – Updates werden geplant, getestet und kontrolliert eingespielt.
Praxisbeispiele: Wer profitiert besonders?
Implementierung: Was ist zu beachten?
Der Aufbau eines KI-Unternehmens-Wiki ist kein Standardprojekt von der Stange. Die folgenden Überlegungen helfen, typische Fehler zu vermeiden und den Aufwand realistisch einzuschätzen.
Fazit
Wissen ist das wertvollste Asset eines Unternehmens. Lokale KI ist nicht die Kompromisslösung – sie ist die bessere Wahl.
Ein KI-gestütztes Unternehmens-Wiki ist keine Science-Fiction und kein Luxus für Grosskonzerne. Die Kombination aus RAG-Architektur, lokalem LLM und Vektordatenbank liefert das Beste aus beiden Welten: die Intelligenz moderner KI und die vollständige Kontrolle über die eigenen Daten. Cloud-KI mag für einzelne Experimente praktisch sein – für unternehmensweiten, dokumentenintensiven Einsatz ist sie zu teuer, zu intransparent und zu riskant. Ihr Wissen bleibt bei Ihnen. Und es wird endlich so zugänglich, wie es sein sollte.
📚 Glossar
- Auftragsverarbeitung (Art. 28 DSGVO)Rechtliche Anforderung, wenn ein Unternehmen personenbezogene Daten durch einen Dritten verarbeiten lässt. Erfordert einen schriftlichen Auftragsverarbeitungsvertrag (AVV).
- ChunksTextabschnitte, in die ein Dokument für die Indexierung aufgeteilt wird. Die optimale Grösse hängt vom Dokumenttyp ab – typisch sind 300 bis 800 Wörter mit Überlappung.
- deprecatedAbkündigung: Der Anbieter stellt den Betrieb einer Modellversion zu einem festgelegten Datum ein. Kunden müssen migrieren, ob sie wollen oder nicht.
- Drittlandtransfer nach Art. 44 ff. DSGVOÜbermittlung personenbezogener Daten in Länder ausserhalb der EU/des EWR (z. B. USA, UK), die gesondert gerechtfertigt werden muss.
- Embedding-ModellWandelt Text in einen hochdimensionalen Zahlenvektor um, der die semantische Bedeutung des Textes kodiert.Definition ansehen ↗
- EU AI Act (Verordnung (EU) 2024/1689)EU-weite KI-Verordnung, die seit August 2024 schrittweise in Kraft tritt. Sie reguliert KI-Systeme nach Risikoklassen und stellt Transparenz- und Dokumentationspflichten.
- Large Language Model (LLM)Ein KI-Modell, das auf enormen Mengen menschlicher Texte trainiert wurde und Sprache verstehen sowie erzeugen kann.Definition ansehen ↗
- Private CloudCloud-Umgebung, die ausschliesslich für ein Unternehmen betrieben wird – im Gegensatz zur Public Cloud, bei der Infrastruktur geteilt wird.
- RAGRetrieval-Augmented Generation – Architekturmuster, bei dem ein LLM zur Antwortgenerierung relevante Textabschnitte aus einer Wissensbasis abruft.Definition ansehen ↗
- RAGASRetrieval-Augmented Generation Assessment – Framework zur systematischen Messung der Qualität von RAG-Systemen anhand von Metriken wie Faithfulness, Answer Relevancy und Context Recall.
- semantisch erschliesstBedeutungsbasierte Verarbeitung von Text – das System versteht den Sinn einer Frage, nicht nur ihre Schlüsselwörter.
- semantische ÄhnlichkeitGemessen z. B. als Cosine Similarity – der Winkel zwischen zwei Vektoren im Vektorraum. Ein Winkel von 0° bedeutet identische Bedeutung, 90° bedeutet unverwandt.
- VektordatenbankSpezialdatenbank zum Ablegen und effizienten Suchen von Embedding-Vektoren nach semantischer Ähnlichkeit.Definition ansehen ↗
KI-Beratung, KI-Lösungen
Leistungsangebot:
- Erstberatung inkl. Machbarkeitsaussagen
- Schulungen und Workshops für Führungskräfte, Berufsgeheimnisträger, Angestellte, Entwickler
- KI-Lösungen mit und ohne ChatGPT/Azure. Cloud oder eigener KI-Server
 Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die
Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die