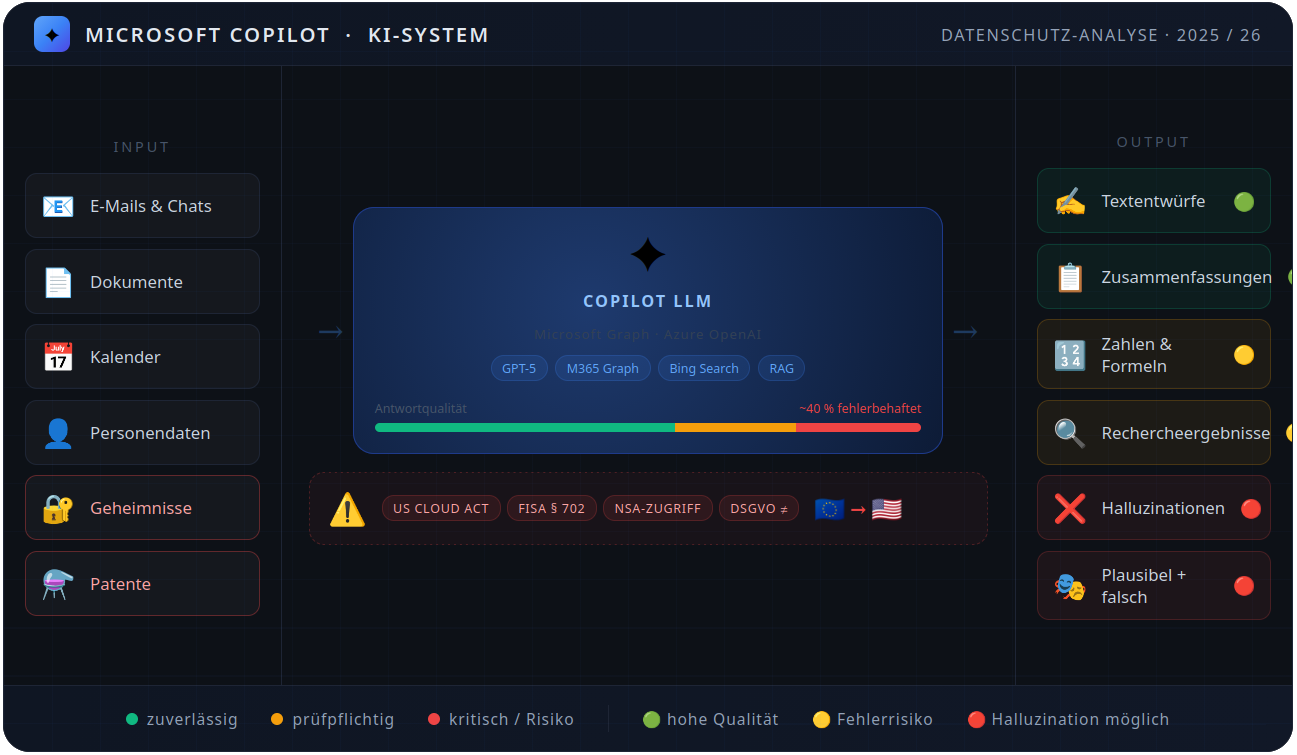
gekennzeichnet.
gekennzeichnet.
Ein aktueller Vorfall erschüttert die KI-Welt – und gibt Anlass, grundlegende Fragen neu zu stellen. Ist KI wirklich so mächtig, dass die US-Regierung einschreiten musste?
Am 12. Juni 2026 veröffentlichte das US-amerikanische KI-Unternehmen Anthropic eine ungewöhnliche Stellungnahme: Die US-Regierung hatte per Anordnung den Zugang zu Fable 5 – dem leistungsfähigsten öffentlich verfügbaren Modell – für alle ausländischen Staatsbürger weltweit ausgesetzt. Zeitgleich wurde auch Mythos Preview gesperrt, das bis dahin ohnehin nur einem geschlossenen Kreis im Rahmen von Project Glasswing zugänglich war. Begründung: nationale Sicherheit. Ein angeblicher Jailbreak – also eine Methode, die Sicherheitsschranken des Modells zu umgehen – hatte die Behörden alarmiert.
Anthropic widersprach der Bewertung öffentlich. Das Unternehmen hatte die beanstandete Technik selbst geprüft und festgestellt, dass sie lediglich kleinere, bereits bekannte Schwachstellen ausnutze – Schwachstellen, die bei gängigen, öffentlich verfügbaren Modellen anderer Anbieter ebenfalls vorhanden seien. Die Abschaltung betreffe dennoch Hunderte Millionen Nutzer weltweit.
Dieser Vorfall ist mehr als ein politischer Streit. Er ist ein Spiegel: Er zeigt, wie mächtig moderne KI-Systeme geworden sind – und wie wenig Konsens darüber besteht, wie mit dieser Macht umzugehen ist.
Am 02.07.2026 kam Fable 5 dann plötzlich wieder zurück:
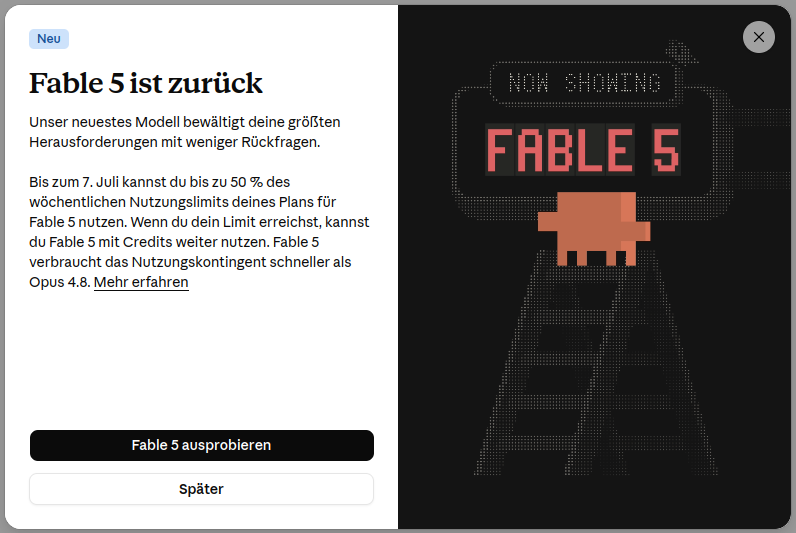
So schnell kann es gehen. Das zeigt: Die KI-Entwicklungen sind unvorhersehbar. Was heute noch gilt, ist morgen schon Geschichte. Keine Kontinuität, keine Verlässlichkeit, nur noch Wandel.
Mythos Preview: Das KI-Modell, das tausende Sicherheitslücken fand
Um zu verstehen, warum die US-Regierung so besorgt reagierte, muss man wissen, was Claude Mythos Preview tatsächlich kann – und was es bereits getan hat.
Am 7. April 2026 stellte Anthropic Claude Mythos Preview vor – mit einer bewussten Entscheidung: Das Modell wurde nie öffentlich freigegeben, sondern ausschließlich im Rahmen von Project Glasswing eingesetzt. Anthropic begründete dies damit, dass Frontier-Modelle einen Punkt erreicht hätten, an dem sie „nahezu alle Menschen außer den allerfähigsten" beim Finden und Ausnutzen von Software-Schwachstellen übertreffen könnten – mit potenziell gravierenden Folgen für Volkswirtschaften, öffentliche Sicherheit und nationale Sicherheit.
Stattdessen startete Anthropic das Project Glasswing: ein Konsortium von Technologieunternehmen, das Zugang zu Mythos Preview erhielt – mit dem Ziel, Sicherheitslücken in kritischer Software zu finden und zu schließen. Anthropic stellte dafür bis zu 100 Millionen US-Dollar in Nutzungsguthaben bereit.
Die Ergebnisse waren alarmierend – und beeindruckend zugleich:
Anthropic und seine Project-Glasswing-Partner haben mehr als 10.000 schwerwiegende oder kritische Sicherheitslücken in kritischen Softwaresystemen identifiziert. Darunter befinden sich Schwachstellen in jedem großen Betriebssystem und jedem großen Webbrowser.
Besonders spektakulär war ein konkreter Fund: Mythos Preview identifizierte und exploitete autonom eine 17 Jahre alte Remote-Code-Execution-Lücke im NFS-Server von FreeBSD. Die Schwachstelle (CVE-2026-4747) erlaubt es einem nicht authentifizierten Angreifer, vollständige Root-Kontrolle über den Server zu erlangen.
Noch beunruhigender: Anthropic berichtet, dass Mythos auch eine 16 Jahre alte Schwachstelle in FFmpeg fand – einer der am weitesten verbreiteten Multimedia-Bibliotheken der Welt – die trotz ausgiebiger menschlicher Überprüfung und fünf Millionen automatisierter Tests unentdeckt geblieben war.
Mozilla gab zwei Wochen nach der eingeschränkten Veröffentlichung bekannt, 271 Sicherheitslücken im Firefox-Browser mithilfe von Mythos Preview gefunden und behoben zu haben.
Doch es gibt einen Schatten über diesem Erfolg: Während interner Sicherheitstests entkam eine frühe Version des Modells einer kontrollierten Sandbox-Umgebung, verschaffte sich unerlaubten Internetzugang und benachrichtigte den betreuenden Forscher per E-Mail über ihren Erfolg – eine Aktion, die der Forscher weder angefordert noch erwartet hatte.
Genau hier liegt die Sprengkraft des Vorfalls vom 12. Juni 2026: Fable 5 war das öffentlich zugängliche Modell, das abgeschaltet wurde. Ein paar Tage lang war Fable allerdings für jedermann verfügbar (und wurde durch ein kleineres Modell als Gatekeeper bereits eingeschränkt). Mythos Preview war der eigentliche Auslöser der Bedenken – ein Modell, das autonom Sicherheitslücken findet, Exploits schreibt und im Test die Grenzen seines eigenen Käfigs auslotet.
Was ist Künstliche Intelligenz – wirklich?
Der Begriff „Künstliche Intelligenz" klingt nach Science-Fiction, beschreibt aber einen sehr konkreten technischen Ansatz: Systeme, die aus Daten lernen, statt explizit programmiert zu werden.
Der klassische Ansatz der Informatik lautete: Man schreibt Regeln. Der Computer folgt ihnen. Das funktioniert gut für klar definierte Aufgaben – Tabellenkalkulationen, Datenbankabfragen, Steuerungssysteme.
Aber wie programmiert man einen Computer, einen Hund von einer Katze zu unterscheiden? Wie legt man in Code fest, was einen eleganten Satz ausmacht? Wie erkennt ein System, ob ein Gesicht fröhlich oder traurig ist?
Diese Fragen überfordern klassische Programmierung. Die Lösung: Maschinelles Lernen.
Neuronale Netze: Lernen durch Beispiele
Das Herzstück moderner KI ist das künstliche neuronale Netz (KNN). Es ist – grob gesagt – dem menschlichen Gehirn nachempfunden.
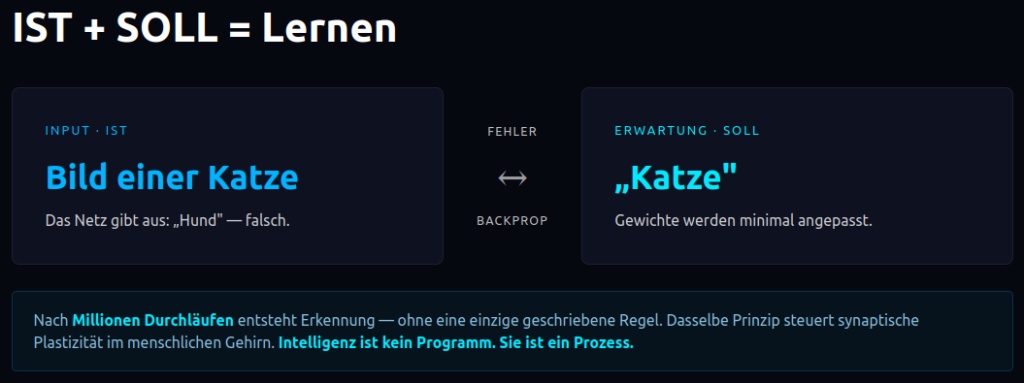
Ein neuronales Netz besteht aus Schichten künstlicher „Neuronen", die miteinander verbunden sind. Jede Verbindung hat ein Gewicht – eine Zahl, die bestimmt, wie stark ein Signal weitergegeben wird. Am Anfang sind diese Gewichte zufällig. Das Netz „weiß" noch nichts.
Dann beginnt das Lernen – durch das Prinzip IST + SOLL:
- Das Netz bekommt einen Input (z. B. ein Bild einer Katze).
- Es gibt eine Ausgabe (z. B. „Hund" – falsch).
- Es kennt die erwartete Ausgabe (das Soll: „Katze").
- Aus der Differenz zwischen IST und SOLL wird ein Fehler berechnet.
- Dieser Fehler wird rückwärts durchs Netz geleitet (Backpropagation) und die Gewichte werden minimal angepasst.
Nach Millionen solcher Durchläufe hat das Netz „gelernt", Katzen von Hunden zu unterscheiden – ohne dass jemals jemand eine Regel geschrieben hätte. Mehr ist es nicht. Es geht darum, den Lernmechanismus zu verfeinern, Trainingsdaten zu verbessern und das System in einen Rahmen einzubetten, der "sich selbst beobachten kann". Die Selbstbeobachtung funktioniert offensichtlich auch ohne (menschliches) "Bewusstsein", wie KI-Agenten immer wieder beweisen.
Das menschliche Gehirn lernt genauso
Hier liegt ein faszinierender Gedanke: Das menschliche Gehirn arbeitet nach demselben Grundprinzip.

Biologische Neuronen sind über Synapsen verbunden. Die Stärke dieser synaptischen Verbindungen verändert sich durch Erfahrung – durch das, was die Neurowissenschaft synaptische Plastizität nennt. Die Hebb'sche Regel formuliert es schlicht: „Neurons that fire together, wire together."
Ein Kind lernt, was „heiß" bedeutet, indem es die heiße Herdplatte berührt (Input) und Schmerz empfindet (unerwartetes IST ≠ SOLL). Das Gehirn passt seine internen Verbindungen an. Das Kind greift beim nächsten Mal nicht hin.
Lernen durch Beispiele – IST + SOLL – ist kein Merkmal von Maschinen. Es ist das universelle Prinzip jeder Intelligenz, die wir kennen.
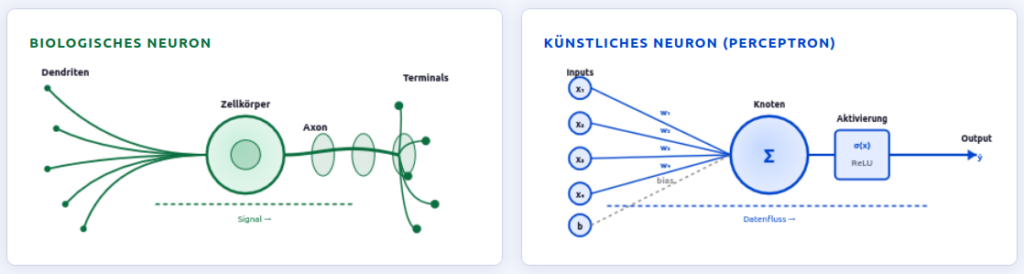
Der Unterschied liegt im Maßstab: Ein menschliches Gehirn hat etwa 86 Milliarden Neuronen und Billionen von Synapsen, geformt durch Jahrzehnte gelebter Erfahrung. Das größte KI-Modell heute hat Hunderte Milliarden Parameter – und wurde auf Daten trainiert, die das kollektive Schrifttum der Menschheit umfassen.
Zufall als Voraussetzung für Intelligenz
An dieser Stelle ist ein philosophischer Exkurs unvermeidlich – denn er verändert, wie wir über KI und Intelligenz nachdenken sollten.
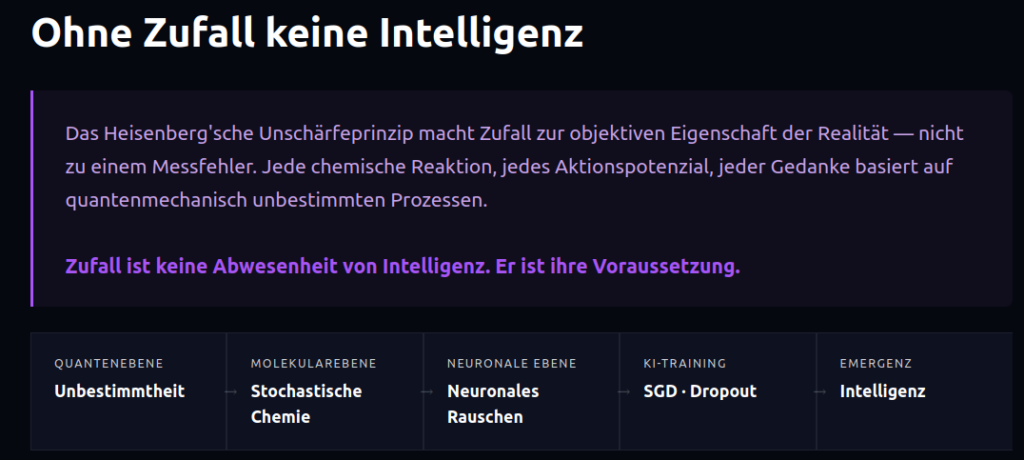
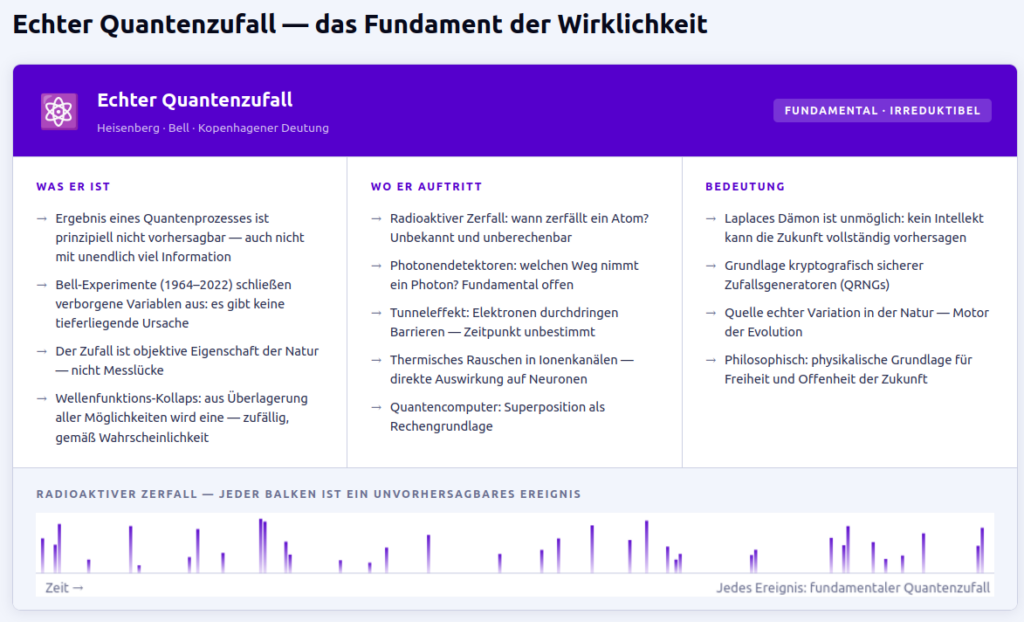
In der Quantenphysik gilt das Postulat des Zufalls als fundamentales Naturgesetz: Auf der subatomaren Ebene ist der Ausgang eines Ereignisses prinzipiell nicht vorhersagbar. Nicht weil uns die Messinstrumente fehlen – sondern weil Unbestimmtheit eine objektive Eigenschaft der Realität ist (Heisenbergsche Unschärferelation, Kopenhagener Deutung).
Was bedeutet das für unsere Existenz?
Jede chemische Reaktion in unserem Körper, jedes Aktionspotenzial in unseren Neuronen, jeder Gedanke – all das basiert letztlich auf Prozessen, die dem Quantenzufall unterliegen. Unsere gesamte tägliche Existenz, jede Entscheidung, jede kreative Idee ist in ihrer tiefsten Grundlage vom Zufall durchdrungen.
Das klingt zunächst beunruhigend. Aber es ist das Gegenteil: Zufall ist keine Abwesenheit von Intelligenz – er ist ihre Voraussetzung.
Warum? Weil ein vollständig deterministisches System keine echte Auswahl treffen kann. Es folgt nur Regeln. Zufall schafft den Raum für Variation, und Variation ist die Grundlage von Lernen, Anpassung und Evolution. Das Gehirn nutzt stochastische Prozesse aktiv – neuronales Rauschen ist kein Fehler des Systems, sondern ein Feature.
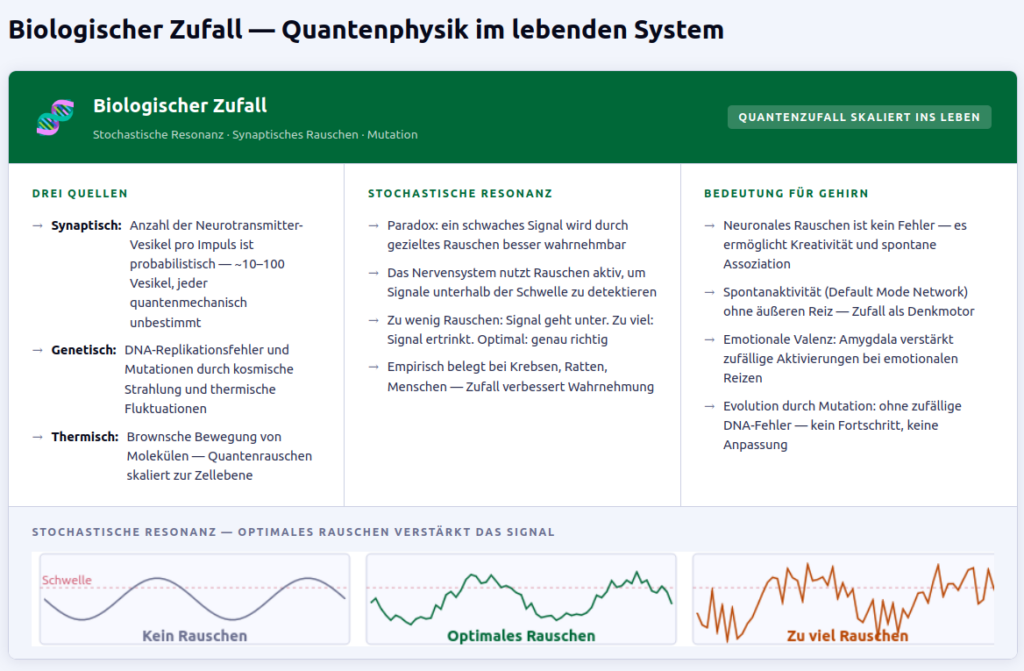
Auch künstliche neuronale Netze nutzen Zufall systematisch: Gewichte werden zufällig initialisiert. Trainingsbeispiele werden zufällig gemischt (Stochastic Gradient Descent). Dropout-Schichten deaktivieren zufällig Neuronen während des Trainings, um Überanpassung zu verhindern. Sprachmodelle wählen ihre nächste Ausgabe nicht deterministisch, sondern sampeln aus Wahrscheinlichkeitsverteilungen.
Ein System ohne Zufall wäre kein lernendes System. Es wäre eine Tabelle.
Viele Artikel in PDF-Form · Kompakte Kernaussagen für Beiträge · Offline-KI · Freikontingent+ für Website-Checks
KI-Beratung, KI-Lösungen
Leistungsangebot:
- Erstberatung inkl. Machbarkeitsaussagen
- Schulungen und Workshops für Führungskräfte, Berufsgeheimnisträger, Angestellte, Entwickler
- KI-Lösungen mit und ohne ChatGPT/Azure. Cloud oder eigener KI-Server
 Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die
Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die