gekennzeichnet.
gekennzeichnet.

Stellen Sie sich vor, Sie könnten einem neuen Mitarbeiter am ersten Tag Zugriff auf das gesamte Wissen Ihres Unternehmens geben – nicht durch stundenlanges Einlesen, sondern durch ein System, das Fragen in natürlicher Sprache beantwortet und dabei genau zeigt, aus welchem Dokument die Antwort stammt. Genau das leistet eine KI-Datenbank.
Dieser Artikel erklärt, was hinter dem Begriff steckt, wie die Technologie funktioniert und warum der Unterschied zu einer gewöhnlichen Datenbank größer ist, als er zunächst erscheint.
Warum Informationen im Unternehmen so schwer zugänglich sind
Wissen ist in jedem Unternehmen vorhanden – aber selten dort, wo man es gerade braucht. Es steckt in PDF-Berichten auf einem Netzlaufwerk, in E-Mail-Anhängen, in alten Excel-Tabellen, in SharePoint-Ordnern, im Handbuch des ERP-Systems oder im Kopf erfahrener Mitarbeiter, die es irgendwann in ein Word-Dokument geschrieben haben.
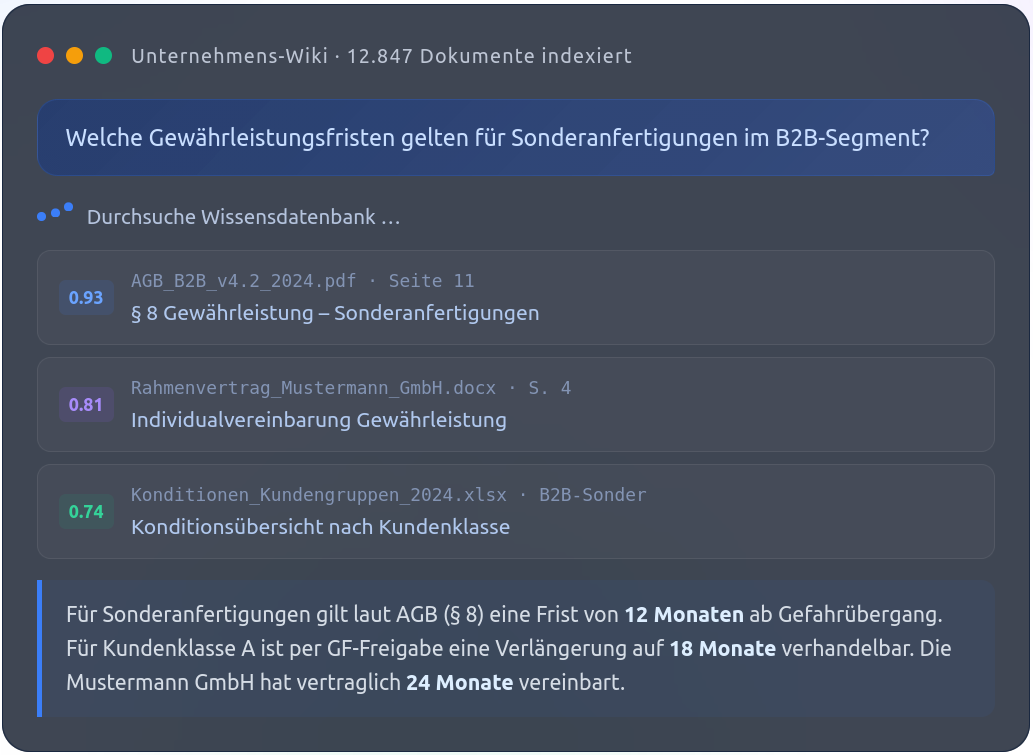
Das Problem ist nicht das fehlende Wissen, sondern die fehlende Zugänglichkeit. Klassische Suchwerkzeuge helfen nur bedingt: Sie durchsuchen Dateinamen und Volltexte nach Schlagwörtern – und liefern im besten Fall eine Liste von Dokumenten, die man dann selbst durcharbeiten muss. Wer nach „Gewährleistungsfrist Lieferant" sucht, bekommt vielleicht zwanzig Treffer. Die eigentliche Antwort auf die Frage muss man trotzdem selbst finden.
Genau hier setzt Künstliche Intelligenz an. Die folgende Animation veranschaulicht die Architektur einer KI-Datenbank, an die ein KI-Modell (Antwort-Engine) angeschlossen ist.
 Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die IT Logic GmbH, berät Kunden und bietet Webseiten-Checks sowie optimierte & sichere Lösungen an (mit und ohne KI).
Mein Name ist Klaus Meffert. Ich bin promovierter Informatiker und beschäftige mich seit über 30 Jahren professionell und praxisbezogen mit Informationstechnologie. In IT & Datenschutz bin ich auch als Sachverständiger tätig. Ich stehe für pragmatische Lösungen mit Mehrwert. Meine Firma, die IT Logic GmbH, berät Kunden und bietet Webseiten-Checks sowie optimierte & sichere Lösungen an (mit und ohne KI).